") 偲偟偨偲偒丄
偲偟偨偲偒丄暯嬒(嶼弍暯嬒)
 偼丄屄乆偺應掕抣偺憤榓傪媮傔丄
偼丄屄乆偺應掕抣偺憤榓傪媮傔丄偦傟傪憤悢偱妱傟偽偱傞丅
偮傑傝丄
嶲峫暥專丂乽揹婥揹巕岺妛偺偨傔偺悢抣寁嶼朄擖栧乿嫶杮廋愭惗
摨堦検偺n夞偺應掕抣傪偲偟偨偲偒丄
暯嬒(嶼弍暯嬒)偼丄屄乆偺應掕抣偺憤榓傪媮傔丄
偦傟傪憤悢偱妱傟偽偱傞丅
偮傑傝丄

廤抍x偺暯嬒抣傪昞偡帪偼丄 偲昞偡丅
偲昞偡丅
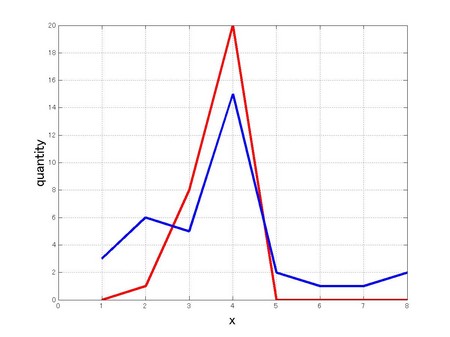
崱恾偺傛偆偵暯嬒抣偑4偩偑僨乕僞偺暘晍偺搙崌偄偑堘偆愒偲惵偺廤抍偑偁傞偲偡傞丅恾傪尒傞偲丄屳偄偵摨偠暯嬒抣傪帩偭偰偄傞偑丄暘晍忬懺偑傑傞偱堘偆偙偲偑傢偐傞丅偦偙偱丄
暯嬒抣偲偼暿偵廤抍偺暘晍偺僶儔僣僉傪昞偡傕偺偑偁傟偽偦傟傕傑偨廤抍偺峔憿傪昞偡巜昗偲側傞
愒偱帵偡恾偱偼丄5,6,7,8偺僨乕僞偼偳傟傕0偩偑惵慄偱偼僨乕僞偑彮偟偢偮懚嵼偟偰偄傞丅
偦偙偱丄屄乆偺僨乕僞偲暯嬒抣偲偺嵎傪偲傟偽丄側傫偲側偔僶儔僣僉偖偁偄傪悢幃偱昞尰偱偒偦偆偱偁傞丅
偙偺奺應掕抣偐傜暯嬒抣傪堷偄偨傕偺傪曃嵎偲屇傇丅

偙偺曃嵎傪慡偰偺x偵偮偄偰寁嶼偟丄偦偺憤榓傪庢傟偽僶儔僣僉偺広搙偑摼傜傟偦偆側婥偑偡傞偑丄幚嵺偵傗偭偰傒傞偲曃嵎偺僾儔僗抣偲儅僀僫僗抣偑懪偪徚偟偁偭偰丄偦偺憤榓偼忢偵僛儘偵側偭偰偟傑偆丅
偙偺偙偲偙偦偑暯嬒抣偺惈幙偱偁傝丄暯嬒抣偲偼曃嵎偺憤榓偑僛儘偵側傞偙偲偱偁傞偺偩丅
偦偙偱丄
僶儔僣僉偺広搙傪媮傔傞偨傔偵丄曃嵎偺晞崋傪徚偡->2忔偡傞
偦偺2忔偟偨曃嵎傪僨乕僞偺憤悢偱妱傟偽僶儔僣僉偑媮傔傜傟傞丅
偦偺僶儔僣僉偺広搙傪暘嶶偲屇傃 偱昞偝傟傞丅
偱昞偝傟傞丅
(曣廤抍偺暘嶶偲偄偆偙偲偱曣暘嶶偲傕偄偆)
^2")
曣暘嶶 偑曣廤抍偺僶儔僣僉傪昞偡広搙偱偁傞偐傜偦偺暯曽崻
偑曣廤抍偺僶儔僣僉傪昞偡広搙偱偁傞偐傜偦偺暯曽崻 傕傑偨曣廤抍偺僶儔僣僉偺広搙傪昞偡偼偢偱偁傞丅
傕傑偨曣廤抍偺僶儔僣僉偺広搙傪昞偡偼偢偱偁傞丅
偙偺 傪昗弨曃嵎(曣昗弨曃嵎)偲屇傇丅
傪昗弨曃嵎(曣昗弨曃嵎)偲屇傇丅
婔壗妛揑偵俀忔偡傞帠偼柺愊傪昞偟丄偦偺暯曽崻偼慄暘傪堄枴偟偰傞丅 偼偦偺寁嶼幃偵偍偄偰丄暯嬒曄壔棪偲夝庍偱偒丄偙傟偼旝暘學悢偲偟偰偺堄枴傪帩偭偰偄傞丅
偼偦偺寁嶼幃偵偍偄偰丄暯嬒曄壔棪偲夝庍偱偒丄偙傟偼旝暘學悢偲偟偰偺堄枴傪帩偭偰偄傞丅 偼丄暯嬒曄壔棪偑曄壔偡傞揰乮曄嬋揰乯偐傜暘晍偺拞怱乮暯嬒抣乯傑偱偺嫍棧傪昞偟偰偄傞丅
偼丄暯嬒曄壔棪偑曄壔偡傞揰乮曄嬋揰乯偐傜暘晍偺拞怱乮暯嬒抣乯傑偱偺嫍棧傪昞偟偰偄傞丅
偙偺偙偲偵傛傝丄 偺戝偒偝偵傛偭偰暘晍偺宍忬偑暘偐傞.
偺戝偒偝偵傛偭偰暘晍偺宍忬偑暘偐傞.
侾偮偺傕偺傪孞傝曉偟應掕偟偨応崌丄偦偺應掕抣偺暘晍偼暯偨偄暘晍乮 偑戝偒偄乯傛傝愲偭偨暘晍乮
偑戝偒偄乯傛傝愲偭偨暘晍乮 偑彫偝偄乯偺曽偑惛搙偑椙偄偲尵偊傞丅
偑彫偝偄乯偺曽偑惛搙偑椙偄偲尵偊傞丅
婔偮傕偺僨乕僞傪婑偣廤傔偨応崌偵丄 偑戝偒偄偲悶峀偑傝側懡條側暘晍偱偁傝丄
偑戝偒偄偲悶峀偑傝側懡條側暘晍偱偁傝丄 偑彫偝偄偲暯嬒抣偵廤拞偟偰偄傞暘晍偲尵偊傞丅
偑彫偝偄偲暯嬒抣偵廤拞偟偰偄傞暘晍偲尵偊傞丅
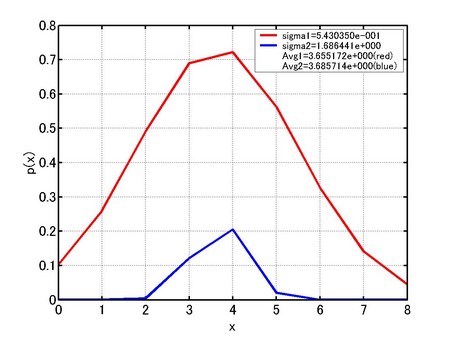
摨偠忦審偱應掕傪孞傝曉偡偲丄嬼慠岆嵎偺偨傔偵應掕抣偼妋棪暘晍傪庢傞偑應掕夞悢偑懡偔側傞偲丄惓婯暘晍(僈僂僗暘晍)偵嬤偯偄偰偄偔丅
應掕抣偑惓婯暘晍傪庢傞偲偒丄應掕抣偑x偲x+dx偺娫偵側傞妋棪傪p(x)dx偲偡傞偲偒丄
 = \frac{1}{\sigma\sqrt(2\pi)}\exp({-\frac{(x-x_m)^2}{2\sigma^2}})")
傪妋棪岆嵎娭悢偲偄偆丅愭傎偳傕彂偄偨偑丄昗弨曃嵎 偼丄暯嬒抣傪拞怱偲偡傞p(x)偺峀偑傝傪帵偟丄應掕抣偺偽傜偮偒偺搙崌偄傪昞偟偰偄傞丅傑偨丄p(x)偼丄x=暯嬒抣偺偲偒偵嵟戝抣
偼丄暯嬒抣傪拞怱偲偡傞p(x)偺峀偑傝傪帵偟丄應掕抣偺偽傜偮偒偺搙崌偄傪昞偟偰偄傞丅傑偨丄p(x)偼丄x=暯嬒抣偺偲偒偵嵟戝抣") 偲側傞丅偮傑傝丄暯嬒抣偑應掕偺嵟妋抣偱偁傞丅傑偨p(x)偺幃偼惓婯壔偝傟偰偍傝丄
偲側傞丅偮傑傝丄暯嬒抣偑應掕偺嵟妋抣偱偁傞丅傑偨p(x)偺幃偼惓婯壔偝傟偰偍傝丄
dx = 1")
偱偁傞丅偙偺悢幃偺堄枴偼應掕抣偺懚嵼妋棪偑 偐傜
偐傜 傑偱傒偨偲偒昁偢懚嵼偡傞偙偲傪堄枴偟偰偄傞丅
傑偱傒偨偲偒昁偢懚嵼偡傞偙偲傪堄枴偟偰偄傞丅
偙偺妋棪岆嵎娭悢偺僌儔僼偺尒曽傪偍偝傜偄偟傛偆丅
椺偊偽丄應掕抣4偲偄偆僨乕僞偑慡應掕抣偺拞偵偳偺偔傜偄偺妱崌偱懚嵼偡傞偐傪尒傞偲偡傞偲丄愒偺僌儔僼偱偼栺70亾偺妋棪偱4偑懚嵼偡傞偙偲偑暘偐傞偺偱偁傞丅媡偵應掕抣8側偳偼5%偺妋棪偱懚嵼偡傞偩傠偆偲偄偆偙偲偑暘偐傞丅
偮傑傝丄偙偺妋棪岆嵎娭悢偲偼奺乆偺應掕抣偺懚嵼妋棪傪帵偟偰偄傞丅
埲壓偵妋擣梡Matlab僗僋儕僾僩傪帵偡丅
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
% 暯嬒丄暘嶶丄昗弨曃嵎
% written by embedded.samurai
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
echo off
clear all
close all
%暯嬒偑係偵側傞傛偆側僨乕僞傪嶌傞
x1=[ 3 4 4 4 2 4 4 4 3 3 4 4 4 4 4 3 4 3 4 4 4 4 4 3 3 4 4 4 3];
x2=[ 1 2 8 4 4 2 4 5 4 4 3 2 4 4 3 4 4 2 3 3 4 3 4 4 4 1 4 1 4 6 8 2 2 7 5 ];
%row偵偼峴丄column偵偼楍偺屄悢偑擖傞丅
[row1 column1]=size(x1);
[row2 column2]=size(x2);
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
% Step1. 暯嬒抣偐傜偺偽傜偮偒傪僌儔僼壔偡傞丅
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
for count=1:1:column1
x1_data(count)=0;
end
for count=1:1:column1
x1_data(x1(count)) = x1_data(x1(count))+1;
end
for count2=1:1:column2
x2_data(count2)=0;
end
for count2=1:1:column2
x2_data(x2(count2)) = x2_data(x2(count2))+1;
end
figure(1)
max1= max(x1)
max2= max(x2)
i1 = [0:1:max1];
i2 = [0:1:max2];
plot(x1_data,'r-','linewidth',3);
hold on
plot(x2_data,'b-','linewidth',3);
grid on
xlabel('x','Fontsize',18)
ylabel('quantity','Fontsize',18)
axis([0 8 0 20]);
print -djpeg distribute.jpeg
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
% Step2. 妋棪岆嵎娭悢傪媮傔傞丅
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
%抣偺崌寁傪嶌傞
%for count=1:1:column
% sum=sum+x1(count);
%end
sum1 = sum(x1);
sum2 = sum(x2);
%暯嬒抣(嶼弍暯嬒)傪媮傔傞
avg1 = sum1/column1
avg2 = sum2/column2
%屄乆偺抣偺曃嵎傪媮傔傞
di1 = x1 - avg1
di2 = x2 - avg2
%僶儔僣僉偺広搙傪媮傔偨偄
%test=0;
%for i=1:1:column
% test = test + di(i);
%end
%test
%曃嵎偺僾儔僗抣偲儅僀僫僗抣偑懪偪徚偟偁偭偰丄偦偺憤榓偼忢偵僛儘偵側傞丅
%暯嬒抣偲偼曃嵎偺憤榓偑僛儘偵側傞偙偲偱偁傞丅
%僶儔僣僉偺広搙傪媮傔傞偨傔偵丄曃嵎偺晞崋傪徚偡->2忔偡傞
%偦偺2忔偟偨曃嵎傪僨乕僞偺憤悢偱妱傟偽僶儔僣僉偑媮傔傜傟傞丅
%偦偺僶儔僣僉偺広搙傪暘嶶偲屇傃\sigma^2偱昞偝傟傞丅
%(曣廤抍偺暘嶶偲偄偆偙偲偱曣暘嶶偲傕偄偆)
%暘嶶傪媮傔傞
%sigma2=0;
%for count=1:1:column
% sigma2 = sigma2 + di(count)^2;
%end
sigma2_1 = sum(di1.^2);
sigma2_2 = sum(di2.^2);
sigma2_1 = sigma2_1/column1
sigma2_2 = sigma2_2/column2
%曣暘嶶\sigma^2偑曣廤抍偺僶儔僣僉傪昞偡広搙偱偁傞偐傜
%偦偺暯曽崻\sigma傕傑偨曣廤抍偺僶儔僣僉偺広搙傪昞偡丅
%偙偺\sigma傪昗弨曃嵎(曣昗弨曃嵎)偲屇傇丅
%昗弨曃嵎傪媮傔傞
sigma_1 = sqrt(sigma2_1)
sigma_2 = sqrt(sigma2_2)
%婔壗妛揑偵俀忔偡傞帠偼柺愊傪昞偟丄偦偺暯曽崻偼慄暘傪堄枴偟偰傞丅
%\sigma偼偦偺寁嶼幃偵偍偄偰丄暯嬒曄壔棪偲夝庍偱偒丄
%偙傟偼旝暘學悢偲偟偰偺堄枴傪帩偭偰偄傞丅
%\sigma偼丄暯嬒曄壔棪偑曄壔偡傞揰乮曄嬋揰乯偐傜暘晍偺拞怱乮暯嬒抣乯
%傑偱偺嫍棧傪昞偟偰偄傞丅
%偙偺偙偲偵傛傝丄\sigma偺戝偒偝偵傛偭偰暘晍偺宍忬偑暘偐傞.
%侾偮偺傕偺傪孞傝曉偟應掕偟偨応崌丄
%偦偺應掕抣偺暘晍偼暯偨偄暘晍乮\sigma偑戝偒偄乯
%傛傝愲偭偨暘晍乮\sigma偑彫偝偄乯偺曽偑惛搙偑椙偄偲尵偊傞丅
%婔偮傕偺僨乕僞傪婑偣廤傔偨応崌偵丄
%\sigma偑戝偒偄偲悶峀偑傝側懡條側暘晍偱偁傝丄
%\sigma偑彫偝偄偲暯嬒抣偵廤拞偟偰偄傞暘晍偲尵偊傞丅
%妋棪岆嵎娭悢傪媮傔傞
max1= max(x1)
max2= max(x2)
i1 = [0:1:max1];
i2 = [0:1:max2];
p1 = 1/(sigma_1*sqrt(2*pi))*exp(-((i2-avg1).^2 / 2*sigma2_1));
hold on;
p2 = 1/(sigma_2*sqrt(2*pi))*exp(-((i2-avg2).^2 / 2*sigma2_2));
figure(2)
plot(i2,p1,'r-','linewidth',3);
hold on
plot(i2,p2,'b-','linewidth',3);
grid on
xlabel('x','Fontsize',18)
ylabel('p(x)','Fontsize',18)
cavg1 = sprintf('Avg1=%d(red)',avg1);
csigma1 = sprintf('sigma1=%d',sigma_1);
cavg2 = sprintf('Avg2=%d(blue)',avg2);
csigma2 = sprintf('sigma2=%d',sigma_2);
h=legend(csigma1,...,
csigma2,...,
cavg1,...,
cavg2,...,
1);
set(h,'FontSize',13)
h=gca
set(h,'LineWidth',2,...,
'FontSize',18)
print -djpeg dispersion.jpeg